Overview
This post will cover using Retreival Augmented Generation (RAG) for Offensive Security purposes. I will show how I developed a RAG service that leverages all of my notes and PDF books to have a specialized resource for Offensive Security related topics. Checkout my project on GitHub where I released my RAG project for open source usage.
RAG
Retrival Augmented Generation (RAG) is a technique used to improve the contextual output of a large language model (LLM) such as ChatGPT. This is done by leveraging a data source outside of the LLMs known knowledge base (Ex: relational database), allowing for optimiziation in the model responses. Using RAG essentially extends the capabilities of your chosen LLM without the costly need of training your own.
Usage Benefits
- You have source information that can be referenced in the responses.
- The information will typically be more current.
- A much more cost effective approach than training your own LLM and fine-tuning.
- The data presented to the user can be more customized.
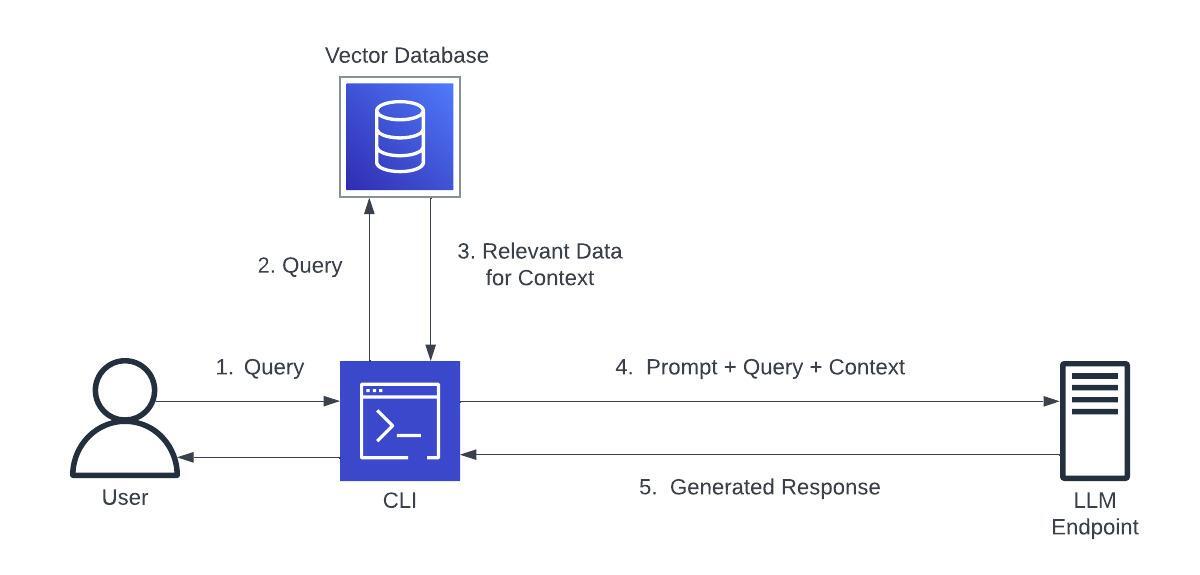
How does RAG work?
Depending on how you architect the service this can vary, but from a general standpoint:
- A user makes a query to an LLM
- The query is then redirected to an external source to pull any relevant data based on the query.
- A new prompt is created with the external source data.
- The prompt with the query are then sent to the LLM to generate a response.
Development
I started doing research on how I could develop a service for myself leverage RAG for my security notes and books. There are numerous open source projects at this point on RAG. I decided to go with this one on GitHub: https://github.com/pixegami/langchain-rag-tutorial
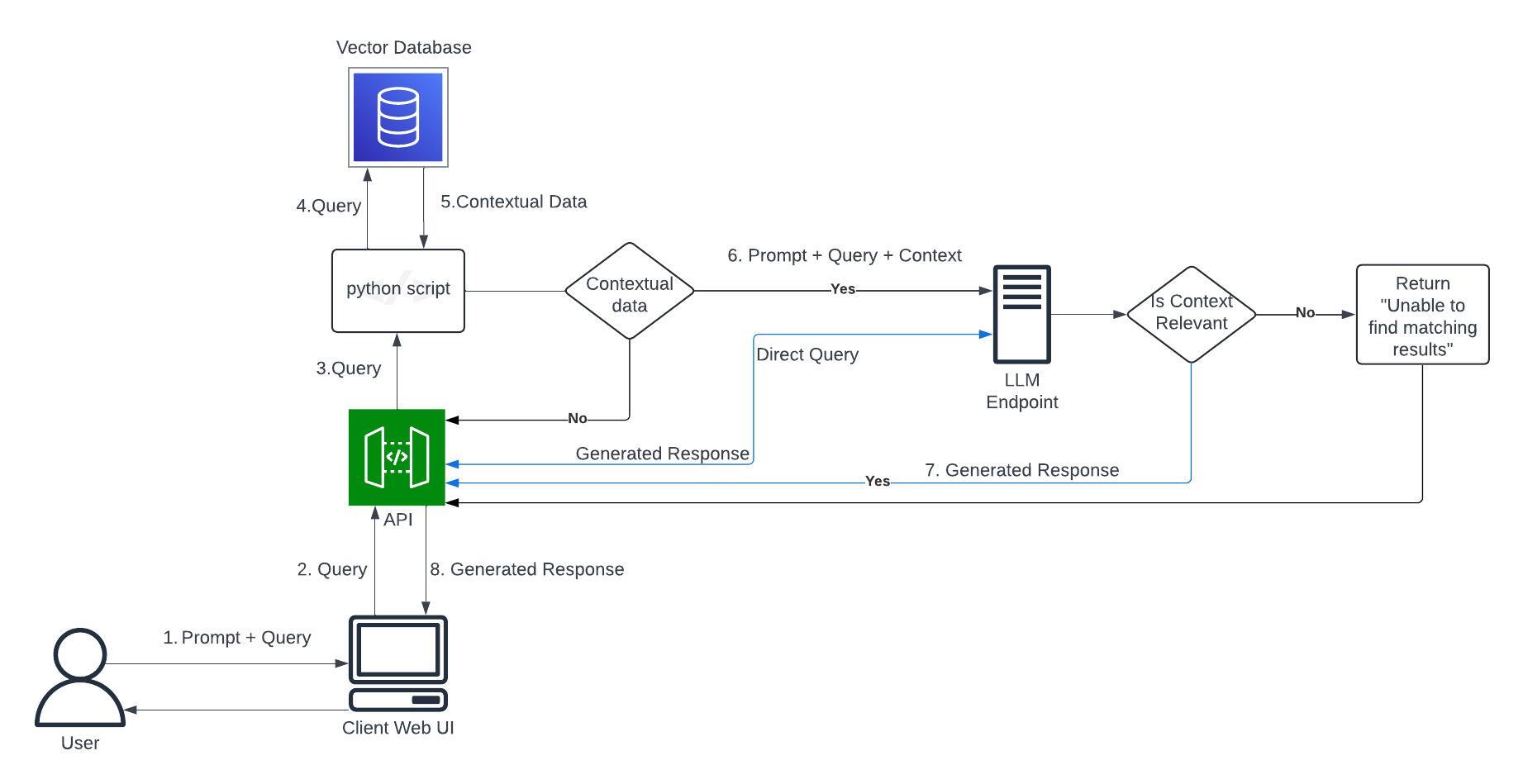
Architecture v1
This is the initial architecture of the RAG service using the CLI and a python script.
Project Structure
At a high level:
- Chromadb is the relational database used for the RAG service.
- All the files that get ingested in to the database are stored in
data/ingestas.mdfiles. - The
create_database.pyscript takes all the files stored indata/ingestand creates thechroma.sqlite3database.
Creating the Database
The main things to note from the script are setting the right location to pull the files from (in this case data/ingest), and the chunk size you want per file. The chunk size I’ve set here splits the documents per 2000 characters each. This tends to work better especially when dealing with large code samples.
# Setting the path
CHROMA_PATH = "chroma"
DATA_PATH = "data/ingest"
def main():
print("[+] Creating data store...")
generate_data_store()
def generate_data_store():
documents = load_documents()
chunks = split_text(documents)
save_to_chroma(chunks)
def load_documents():
loader = DirectoryLoader(DATA_PATH, glob="*.md")
documents = loader.load()
return documents
# Setting the chunk size
def split_text(documents: list[Document]):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
chunks = text_splitter.split_documents(documents)
print(f"Split {len(documents)} documents into {len(chunks)} chunks.")
document = chunks[10]
print(document.page_content)
print(document.metadata)
return chunks
def save_to_chroma(chunks: list[Document]):
# Clear out the database first.
if os.path.exists(CHROMA_PATH):
shutil.rmtree(CHROMA_PATH)
# Create a new DB from the documents.
db = Chroma.from_documents(
chunks, OpenAIEmbeddings(), persist_directory=CHROMA_PATH
)
db.persist()
print(f"Saved {len(chunks)} chunks to {CHROMA_PATH}.")
Running the script is then a simple task. I include a time check to see how long the database takes to create. I processed a little over a thousand documents which took around 12 minutes. Timing can also vary base on your OS / VM resources.
> time python3 create_database.py
Querying the Database & LLM
Query Functionality
I’ve since made many updates to the functionality of the query_data.py script so it works in conjunction with a custom API and WebUI. However it is still usable from a basic query standpoint.
The query format is what’s used when sending the data to ChatGPT API.
python3 query_data.py "[Message(role='user', content='what is red teaming?')]" 2>/dev/null
And here is the response when leveraging the RAG database.
~/Lab/Cognition/RAG/Project$ python3 query_data.py "[Message(role='user', content='what is red teaming?')]" 2>/dev/null
Red teaming, in the context of cybersecurity and organizational defense, involves
providing an adversarial perspective by challenging assumptions made by an organization
and its defenders. It aims to identify areas for improvement in operational defense by
simulating adversary decisions or behaviors. Red teaming goes beyond traditional penetration testing
by focusing on specific objectives defined by the organization, emulating real-life threats,
studying and re-using threat tactics, techniques, and procedures (TTPs), and assessing the overall
security posture including people and processes. Red teams also emphasize stealth and the principle
of least privilege to test detection and response capabilities effectively.\
Sources: ['data/ingest/01 - Red Teaming.md', 'data/ingest/redteam-strats.md',
'data/ingest/redteam-strats.md', 'data/ingest/Securing-DevOps.md', 'data/ingest/01 - Red Teaming.md']
So how do we know that it actually leveraged the database? Well, in any instance where this is the case, there will be Sources listed at the bottom as to which documents the data was referenced from.
Prompt Data
This is the prompt being used and sent to ChatGPT API. With this we send the conversation history, the contextual data being pulled from the relational database, and the original query from the user.
The prompt is written in a way where even if there is data pulled from the database, if it does not appear to be relevant the conversation, then it will not be used.
PROMPT_TEMPLATE = """
You are part of an ongoing conversation, this is the previous conversation history.
Note there will be no history if it is the initial request:
{conversation_history}
Answer the following question while considering the previous conversation context to ensure
coherence and relevance. Use the provided context and integrate it with the ongoing discussion:
{context}
---
Note if the context does not align with the conversation history (unless there is no
coversation history yet), return "Unable to find matching results."
If the question asks for a command-line example, ensure that the command is
provided within a code block with syntax highlighting.
Question: {question}
"""
Limitations
While the above program does work, there are a few limiting factors:
- Lack of a UI for ease of use.
- The conversation history is not sustained when using the RAG service via CLI, so you cannot ask follow up questions.
- Any question posed that can’t be found in the database will not be answered. The script will simply state, “unable to find matching results”.
Cognition
With the above limitations noted, this led me to develop the RAG service further to an application I call Cognition, which leverages the following:
- https://github.com/pixegami/langchain-rag-tutorial -> RAG functionality
- https://github.com/anse-app/anse -> Web UI
- ChatGPT -> OpenAI API for the LLM.
- A custom python-based API I developed
Architecture v2
This is the updated architecture which now includes a Web UI and a custom python API that handles the interactions between each component.